Research2026
Comparing Temporal Logic Reward Shaping Approaches in Reinforcement Learning
Research on dense and sparse reward shaping techniques for temporal logic specifications in reinforcement learning.
Screenshots
About this Research
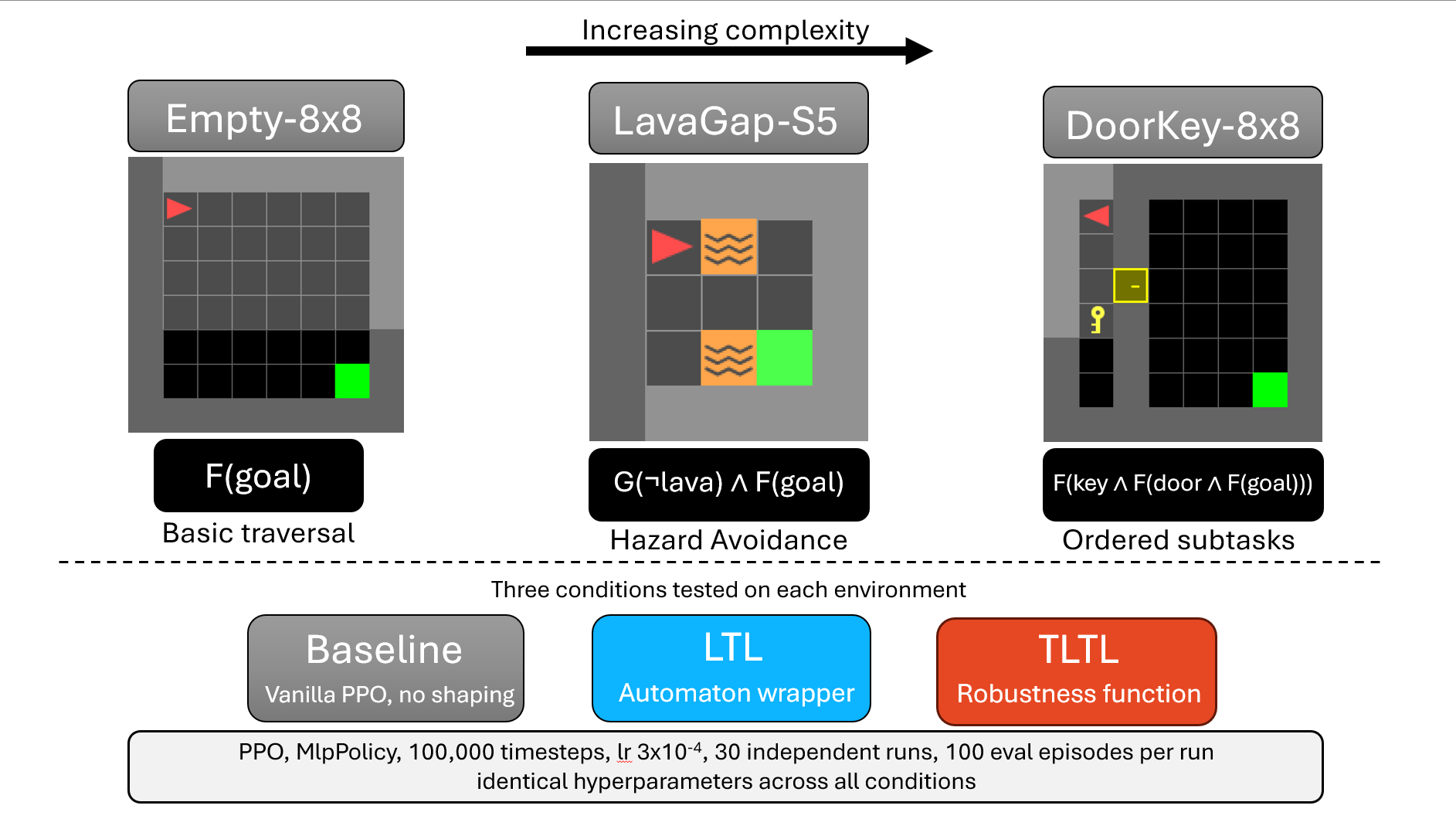
Temporal logic specifications are increasingly used to provide safety and task guarantees for reinforcement learning agents, yet most existing approaches assume infinite-horizon objectives. We empirically compare infinite-horizon automaton-based methods (LTL) with finite-horizon robustness-based formulations (TLTL) across three MiniGrid benchmark environments of increasing complexity, evaluating specification satisfaction probability, mean time to satisfaction, and sample efficiency across 30 independent runs.
Technologies Used
PythonMiniGridGymnasiumPPO